使用 Kafka 和 Docker 开发事件驱动型应用程序
目录
随着微服务的兴起,事件驱动架构越来越受欢迎。 Apache Kafka
随着微服务的兴起,事件驱动架构越来越受欢迎。 Apache Kafka
导航到项目目录。
cd kafka-development-node/app
使用 yarn 安装依赖项。
$ yarn install
使用 yarn dev 启动应用程序。这会将 NODE_ENV 环境变量设置为 development 并使用 nodemon 监视文件更改。
$ yarn dev
应用程序现在正在运行,它会将接收到的消息记录到控制台。在新终端中,使用以下命令发布几条消息
$ docker exec -ti kafka /opt/kafka/bin/kafka-console-producer.sh --bootstrap-server :9092 --topic demo
然后向集群发送一条消息
Test message完成后,请记住按 Ctrl+c 停止生成消息。
现在您有一个应用程序通过其暴露的端口连接到 Kafka,接下来将探讨从另一个容器连接到 Kafka 需要进行哪些更改。为此,您现在将从容器而不是本机运行应用程序。
但在您这样做之前,务必了解 Kafka 侦听器的工作原理以及这些侦听器如何帮助客户端连接。
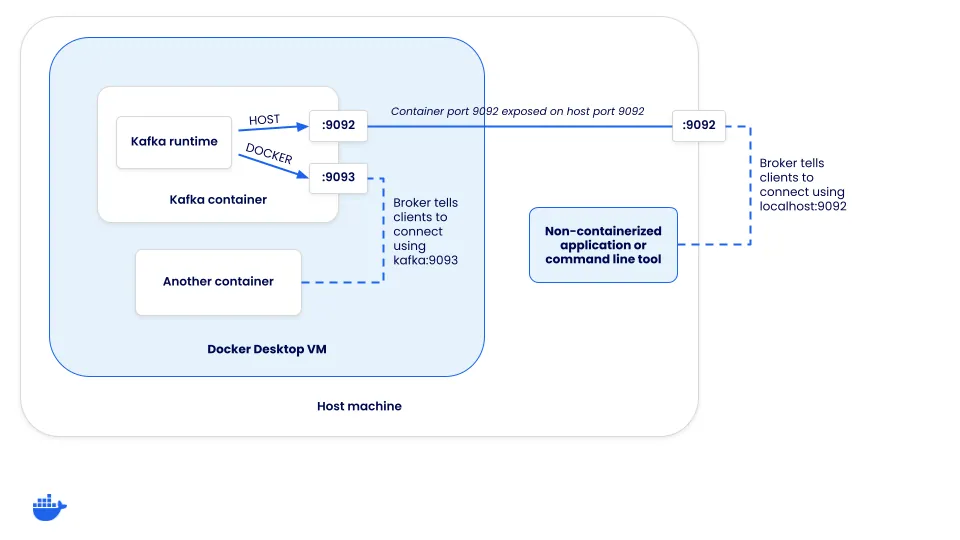
当客户端连接到 Kafka 集群时,它实际上是连接到一个“代理”。虽然代理有很多角色,但其中之一是支持客户端的负载均衡。当客户端连接时,代理会返回一组连接 URL,客户端应使用这些 URL 连接以生成或消费消息。如何配置这些连接 URL?
每个 Kafka 实例都有一组侦听器和已公布的侦听器。“侦听器”是 Kafka 绑定到的内容,“已公布的侦听器”配置客户端应如何连接到集群。客户端接收的连接 URL 基于客户端连接到的侦听器。
为了更好地理解,让我们看看 Kafka 需要如何配置才能支持两种连接方式。
由于客户端需要使用两种不同的连接方法,因此需要两个不同的监听器 - HOST 和 DOCKER。HOST 监听器将指示客户端使用 localhost:9092 连接,而 DOCKER 监听器将指示客户端使用 kafka:9093 连接。请注意,这意味着 Kafka 同时监听端口 9092 和 9093。但是,只有主机监听器需要暴露给主机。
为了进行此设置,Kafka 的 compose.yaml 文件需要一些额外的配置。一旦您开始覆盖某些默认值,您还需要指定其他一些选项才能使 KRaft 模式正常工作。
services:
kafka:
image: apache/kafka-native
ports:
- "9092:9092"
environment:
# Configure listeners for both docker and host communication
KAFKA_LISTENERS: CONTROLLER://localhost:9091,HOST://0.0.0.0:9092,DOCKER://0.0.0.0:9093
KAFKA_ADVERTISED_LISTENERS: HOST://localhost:9092,DOCKER://kafka:9093
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,DOCKER:PLAINTEXT,HOST:PLAINTEXT
# Settings required for KRaft mode
KAFKA_NODE_ID: 1
KAFKA_PROCESS_ROLES: broker,controller
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@localhost:9091
# Listener to use for broker-to-broker communication
KAFKA_INTER_BROKER_LISTENER_NAME: DOCKER
# Required for a single node cluster
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1请按照以下步骤尝试。
如果您正在运行上一步中的 Node 应用程序,请在终端中按 ctrl+c 将其停止。
如果您正在运行上一节中的 Kafka 集群,请使用以下命令停止该容器
$ docker rm -f kafka
在克隆项目目录的根目录下运行以下命令来启动 Compose 堆栈
$ docker compose up
片刻之后,应用程序将启动并运行。
在堆栈中还有另一个服务可用于发布消息。通过访问 http://localhost:3000 来打开它。当您键入消息并提交表单时,您应该会看到应用程序接收消息的日志消息。
这有助于演示容器化方法如何轻松添加其他服务来帮助测试和排除应用程序故障。
一旦您开始在开发环境中使用容器,您就会开始意识到添加专注于帮助开发的其他服务的便利性,例如可视化工具和其他支持服务。由于您正在运行 Kafka,因此可视化 Kafka 集群中发生的事情可能会有所帮助。为此,您可以运行 Kafbat UI Web 应用程序。
要将其添加到您自己的项目中(它已在演示应用程序中),您只需将以下配置添加到您的 Compose 文件中
services:
kafka-ui:
image: ghcr.io/kafbat/kafka-ui:latest
ports:
- 8080:8080
environment:
DYNAMIC_CONFIG_ENABLED: "true"
KAFKA_CLUSTERS_0_NAME: local
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka:9093
depends_on:
- kafka然后,一旦 Compose 堆栈启动,您就可以在浏览器中打开 http://localhost:8080